Neural Machine Translation With PyTorch
Tutorial 1: Encoder-Decoder
Recently I did a workshop about Deep Learning for Natural Language Processing. Clearly, 3 days was not enough to cover all topics in this broad field, therefore I decided to create a series of practical tutorials about Neural Machine Translation in PyTorch. In this series, I will start with a simple neural translation model and gradually improve it using modern neural methods and techniques. In the first tutorial, I will create Ukrainian-German translator using an encoder-decoder model.
Introduction
For almost 25 years, mainstream translation systems used Statistical Machine Translation. SMT methods were not outperformed until 2016 when Google AI released results of their Neural Machine Translation model and started to use it in Google Translation for 9 languages.
Important to notice, that GNMT result was mostly defined by a huge amount of training data and extensive computational power, which makes impossible to reproduce this results for individual researchers. However, ideas and techniques, which were used in this architecture, were reused to solve many other problems: question answering, natural database interface, speech-to-text and text-to-speech and so on. Therefore, any deep learning expert can benefit from an understanding of how modern NMT works.
Theory
Even though I am mostly a practitioner but I still prefer to have a solid mathematical representation of any model I am working with. This allows maintaining a correct level of abstract understanding of a problem which my model is solving. You can skip this part and go to a model definition if you prefer to start coding. But I advise you to review the theoretical part to have a deep understanding of the following implementation.
Given a sentence in source language $\textbf{x}$, the task is to infer a sentence in target language $\textbf{y}$ which maximizes conditional probability $p(\textbf{y}|\textbf{x})$:
\begin{equation} \textbf{y} = \underset{\hat{\textbf{y}}}{\mathrm{argmax}} p(\hat{\textbf{y}}|\textbf{x}) \end{equation}
This equation can not be used as is: there are an infinite number of all possible $\hat{\textbf{y}}$. But since a sentence $\textbf{y}$ is a sequence of words $y_1, y_2, \ldots ,y_{t-1}, y_t$, this probability can be decomposed as a product of probabilities for each word:
\begin{equation} p(\textbf{y}|\textbf{x}) = \prod_{i=1}^{t} p(y_i| \textbf{x}) \end{equation}
Words probabilities in $\textbf{y}$ are not distributed independently; in the natural language phrases and sentences are usually follow strict or non-strict rules for word selection. Therefore, conditional probability for each word should also include other words from a target sentence:
\begin{equation} p(\textbf{y}|\textbf{x}) = \prod_{i=1}^{t} p(y_i|y_{t}, y_{t-1}, \ldots, y_{i+1}, y_{i-1}, \ldots, y_{2}, y_{1}, \textbf{x})\label{xy} \end{equation}
Using a predefined set of words or vocabulary $\textbf{V}$ we can infer from it the target sentence $\textbf{y}$ word by word using this probability: $p(y_i|y_{j\ne i}, \textbf{x})$. The only question is: how to get this probability? And it can be approximated with a neural model.
Let’s denote weights of neural model as $\theta$ and training data as a set of tuples $(\textbf{y}^{(x)}, \textbf{x})$, where each $\textbf{y}^{(x)}$ is a correct translation of $\textbf{x}$. Optimal values of $\theta$ can be found by maximization of a following equation:
\begin{equation} \theta = \underset{\theta}{\mathrm{argmax}} \sum_{\textbf{y}^{(x)}, \textbf{x}} log \ p(\textbf{y}^{(x)}| \textbf{x}; \theta) \label{mle} \end{equation}
\ref{mle} is basically a log-likelihood for a training data. Likelihood maximization means that we train a neural network to produce probabilities, which makes training set $(\textbf{y}^{(x)}, \textbf{x})$ results more likely than any other results.
Model
From equation \ref{xy} you can see, how should be connected information inside of a neural model for machine translation. To infer a word $y_i$ you need to provide the model with data about previous words $y_{<i}$ (since you don’t have next words at the moment when you infer $y_i$, you can only use previous words) and information about a source sentence $\textbf{x}$.
The source sentence is encoded word for word by a Recurrent Neural Network, which is called Encoder. Then the last hidden state of the Encoder is used as the first hidden state of another RNN1. This network decodes a target sentence word for word, and this network is obviously called Decoder. This way a shared hidden state between Encoder and Decoder is used to store all the information the Decoder need to produce a valid probability distribution for $y_i$2.
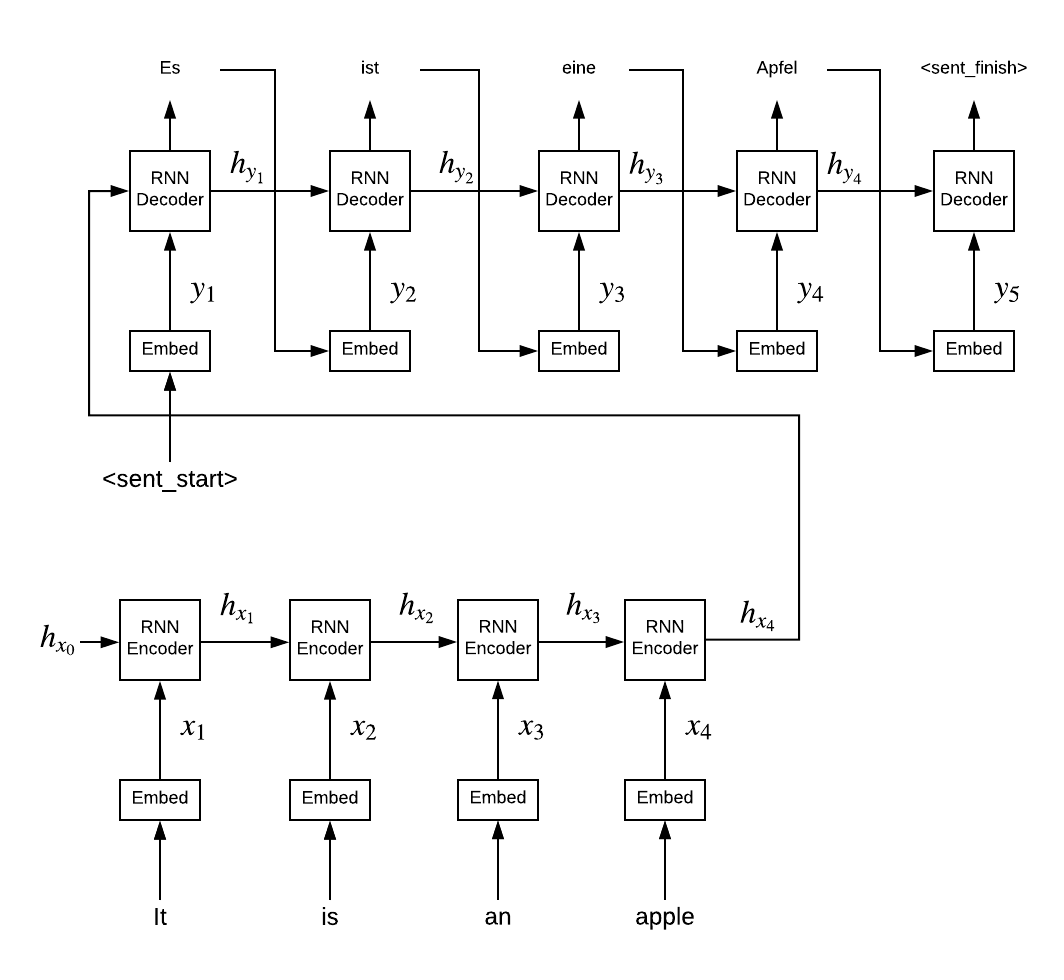 Encoder-Decoder with a thought vector
Encoder-Decoder with a thought vector
Implementation
Data preparation
For this tutorial I used bilingual datasets from tatoeba.org.
You can download language pairs data from http://www.manythings.org/anki/, or if there is no pair (as for Ukrainian-German), you can use my script get_dataset.py. It downloads raw data from tatoeba and extracts a bilingual dataset as a csv file.
import pandas as pd
import os
source_lang = 'ukr'
target_lang = 'deu'
data_dir = 'data/'
os.chdir('../')
corpus = pd.read_csv(os.path.join(data_dir, '{}-{}.csv'.format(source_lang, target_lang)), delimiter='\t')
To train a neural network I need to turn the sentences into something a neural network can understand, which of course means numbers. Each sentence is split into words and turned into a sequence of numbers. To do this, I used a vocabulary – a class which stores word indexes.
SOS_token = '<start>'
EOS_token = '<end>'
UNK_token = '<unk>'
PAD_token = '<pad>'
SOS_idx = 0
EOS_idx = 1
UNK_idx = 2
PAD_idx = 3
class Vocab:
def __init__(self):
self.index2word = {
SOS_idx: SOS_token,
EOS_idx: EOS_token,
UNK_idx: UNK_token,
PAD_idx: PAD_token
}
self.word2index = {v: k for k, v in self.index2word.items()}
def index_words(self, words):
for word in words:
self.index_word(word)
def index_word(self, word):
if word not in self.word2index:
n_words = len(self)
self.word2index[word] = n_words
self.index2word[n_words] = word
def __len__(self):
assert len(self.index2word) == len(self.word2index)
return len(self.index2word)
def unidex_words(self, indices):
return [self.index2word[i] for i in indices]
def to_file(self, filename):
values = [w for w, k in sorted(list(self.word2index.items())[5:])]
with open(filename, 'w') as f:
f.write('\n'.join(values))
@classmethod
def from_file(cls, filename):
vocab = Vocab()
with open(filename, 'r') as f:
words = [l.strip() for l in f.readlines()]
vocab.index_words(words)
Here I defined tokenizer functions for Ukrainian and German to split sentences into words.
I used a standard nltk.tokenize.WordPunctTokenizer for German and
a function tokenize_words from package tokenize_uk for Ukrainian.
Since there are a lot of example sentences and I want to train something quickly, I trimmed the data set to only relatively short and simple sentences. Here the maximum length is 10 words (that includes punctuation).
Additionally, you might want to filter out rare words which occur only a few times in the corpus. This words could not be learned efficiently since there are not enough training examples for them. This will reduce vocabulary size and decrease training time.
import nltk
from tokenize_uk import tokenize_words
import pandas as pd
max_length = 10
min_word_count = 1
tokenizers = {
'ukr': tokenize_words,
'deu': nltk.tokenize.WordPunctTokenizer().tokenize
}
def preprocess_corpus(sents, tokenizer, min_word_count):
n_words = {}
sents_tokenized = []
for sent in sents:
sent_tokenized = [w.lower() for w in tokenizer(sent)]
sents_tokenized.append(sent_tokenized)
for word in sent_tokenized:
if word in n_words:
n_words[word] += 1
else:
n_words[word] = 1
for i, sent_tokenized in enumerate(sents_tokenized):
sent_tokenized = [t if n_words[t] >= min_word_count else UNK_token for t in sent_tokenized]
sents_tokenized[i] = sent_tokenized
return sents_tokenized
def read_vocab(sents):
vocab = Vocab()
for sent in sents:
vocab.index_words(sent)
return vocab
source_sents = preprocess_corpus(corpus['text' + source_lang], tokenizers[source_lang], min_word_count)
target_sents = preprocess_corpus(corpus['text' + target_lang], tokenizers[target_lang], min_word_count)
# Using set to remove duplicates
source_sents, target_sents = zip(
*sorted({(tuple(s), tuple(t)) for s, t in zip(source_sents, target_sents)
if len(s) <= max_length and len(t) <= max_length})
)
source_vocab = read_vocab(source_sents)
target_vocab = read_vocab(target_sents)
target_vocab.to_file(os.path.join(data_dir, '{}.vocab.txt'.format(target_lang)))
source_vocab.to_file(os.path.join(data_dir, '{}.vocab.txt'.format(source_lang)))
print('Corpus length: {}\nSource vocabulary size: {}\nTarget vocabulary size: {}'.format(
len(source_sents), len(source_vocab.word2index), len(target_vocab.word2index)
))
examples = list(zip(source_sents, target_sents))[80:90]
for source, target in examples:
print('Source: "{}", target: "{}"'.format(' '.join(source), ' '.join(target)))
Corpus length: 14044
Source vocabulary size: 8497
Target vocabulary size: 6138
Source: "апельсини ростуть в теплих країнах .", target: "apfelsinen wachsen in warmen ländern ."
Source: "араби мене переслідують .", target: "araber verfolgen mich ."
Source: "арбітр закінчить гру за дві хвилини .", target: "der schiedsrichter wird das spiel in zwei minuten beenden ."
Source: "астронавти полетіли на місяць в ракеті .", target: "die astronauten flogen mit einer rakete zum mond ."
Source: "африка є колискою людства .", target: "afrika ist die wiege der menschheit ."
Source: "африка — не країна .", target: "afrika ist kein land ."
Source: "афіни — столиця греції .", target: "athen ist die hauptstadt griechenlands ."
Source: "афіни — столиця греції .", target: "athen ist die hauptstadt von griechenland ."
Source: "бабусі подобається дивитися телевізор .", target: "oma schaut gerne fernsehen ."
Source: "багато американців цікавляться джазом .", target: "viele amerikaner interessieren sich für jazz ."
As you can see, some translation pairs can duplicate each other: one source sentence might have multiple target references. This naturally happens in language, we always have options for translation. And this should be considered when we train NMT system: that it is possible to have more than one option of a correct model output.
Translation quality metrics like BLEU3 (it will be described in details later) are designed to use multiple references of a correct translation. To take this into account during evaluation I combined pairs with an identical source into one pair with one source and multiple targets.
source_to_target = {}
for source, target in zip(source_sents, target_sents):
if source in source_to_target:
source_to_target[source].append(target)
else:
source_to_target[source] = [target]
source_sents, target_sents = zip(*source_to_target.items())
len(source_sents)
11967
Data for deep learning experiment is usually split into three parts:
- Training data is used for neural network training;
- Development data is used to select an optimal training stop point;
- Test data is used for final evaluation of experiment performance.
I used 80% of the data as a training set, 6% of the data as a development set and 14% of the data as a test set.
import numpy as np
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
source_length = len(source_sents)
inidices = np.random.permutation(source_length)
training_indices = inidices[:int(source_length*0.8)]
dev_indices = inidices[int(source_length*0.8):int(source_length*0.86)]
test_indices = inidices[int(source_length*0.86):]
training_source = [source_sents[i] for i in training_indices]
dev_source = [source_sents[i] for i in dev_indices]
test_source = [source_sents[i] for i in test_indices]
training_target = [target_sents[i] for i in training_indices]
dev_target = [target_sents[i] for i in dev_indices]
test_target = [target_sents[i] for i in test_indices]
# Unwrap training examples
training_t = []
training_s = []
for source, tt in zip(training_source, training_target):
for target in tt:
training_t.append(target)
training_s.append(source)
training_source = training_s
training_target = training_t
PyTorch uses its own format of data – Tensor. It is a multi-dimensional array of numbers with some type e.g. FloatTensor or LongTensor.
Before I can use the training data, I need to convert it into tensors using previously defined word indices. Also, I need to have source sentences as tensors for model validation with development and test sample.
Each sentence in the tensor form should have special tokens SOS (start of a sentence) and EOS (end of a sentence) for a model being able to identify sequence start and finish. Also, all sentences should have the same length to make possible the batch training, therefore I extended them with a token PAD if needed.
import torch
def indexes_from_sentence(vocab, sentence):
return [vocab.word2index[word] for word in sentence]
def tensor_from_sentence(vocab, sentence, max_seq_length):
indexes = indexes_from_sentence(vocab, sentence)
indexes.append(EOS_idx)
indexes.insert(0, SOS_idx)
# we need to have all sequences the same length to process them in batches
if len(indexes) < max_seq_length:
indexes += [PAD_idx] * (max_seq_length - len(indexes))
tensor = torch.LongTensor(indexes)
return tensor
def tensors_from_pair(source_sent, target_sent, max_seq_length):
source_tensor = tensor_from_sentence(source_vocab, source_sent, max_seq_length).unsqueeze(1)
target_tensor = tensor_from_sentence(target_vocab, target_sent, max_seq_length).unsqueeze(1)
return (source_tensor, target_tensor)
max_seq_length = max_length + 2 # 2 for EOS_token and SOS_token
training = []
for source_sent, target_sent in zip(training_source, training_target):
training.append(tensors_from_pair(source_sent, target_sent, max_seq_length))
x_training, y_training = zip(*training)
x_training = torch.transpose(torch.cat(x_training, dim=-1), 1, 0)
y_training = torch.transpose(torch.cat(y_training, dim=-1), 1, 0)
torch.save(x_training, os.path.join(data_dir, 'x_training.bin'))
torch.save(y_training, os.path.join(data_dir, 'y_training.bin'))
x_development = []
for source_sent in dev_source:
tensor = tensor_from_sentence(source_vocab, source_sent, max_seq_length).unsqueeze(1)
x_development.append(tensor)
x_development = torch.transpose(torch.cat(x_development, dim=-1), 1, 0)
torch.save(x_development, os.path.join(data_dir, 'x_development.bin'))
x_test = []
for source_sent in test_source:
tensor = tensor_from_sentence(source_vocab, source_sent, max_seq_length).unsqueeze(1)
x_test.append(tensor)
x_test = torch.transpose(torch.cat(x_test, dim=-1), 1, 0)
torch.save(x_test, os.path.join(data_dir, 'x_test.bin'))
USE_CUDA = False
if USE_CUDA:
x_training = x_training.cuda()
y_training = y_training.cuda()
x_development = x_development.cuda()
x_test = x_test.cuda()
Encoder
The encoder of an Encoder-Decoder network is a Recurrent Neural Network. A recurrent network can model a sequence of related data (sentence in our case) using the same set of weights. To do this, RNN uses its output from a previous step as input along with the next input from a sequence.
A naive implementation of RNN is subject to problems with a gradient for long sequences4; therefore, I used Long-Short Term Memory5 as a recurrent module. You should not care about its implementation since it already implemented in PyTorch: nn.LSTM. This module allows bi-directional sequence processing out-of-the-box – this allows to capture backward relations in a sentence as well as forward relations.
Additionally, I used embeddings module to convert word indices into dense vectors. This allows projecting discrete symbols (words) into continuous space which reflects semantical relations in spatial words positions. For this experiment, I did not use pre-trained word vectors and trained this representation using machine translation supervision signal. But you may use the pre-trained word embeddings for any language6.
To not forget the meaning of dimensions for input vectors, I left comments like # word_inputs: (batch_size, seq_length). Above means that variable word_inputs contains a reference to a tensor, which has shape (batch_size, seq_length), e.g. it is an array of sequences of length seq_length, where array length is batch_size.
import torch.nn as nn
import torch.nn.init as init
class EncoderRNN(nn.Module):
def __init__(self, vocab_size, hidden_size, n_layers=1):
super(EncoderRNN, self).__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.embedding = nn.Embedding(vocab_size, hidden_size)
init.normal_(self.embedding.weight, 0.0, 0.2)
self.lstm = nn.LSTM(
hidden_size,
int(hidden_size/2), # Bi-directional processing will ouput vectors of double size, therefore I reduced output dimensionality
num_layers=n_layers,
batch_first=True, # First dimension of input tensor will be treated as a batch dimension
bidirectional=True
)
# word_inputs: (batch_size, seq_length), h: (h_or_c, layer_n_direction, batch, seq_length)
def forward(self, word_inputs, hidden):
# embedded (batch_size, seq_length, hidden_size)
embedded = self.embedding(word_inputs)
# output (batch_size, seq_length, hidden_size*directions)
# hidden (h: (num_layers*directions, batch_size, hidden_size),
# c: (num_layers*directions, batch_size, hidden_size))
output, hidden = self.lstm(embedded, hidden)
return output, hidden
def init_hidden(self, batches):
hidden = torch.zeros(2, self.n_layers*2, batches, int(self.hidden_size/2))
if USE_CUDA: hidden = hidden.cuda()
return hidden
Decoder
Decoder module is similar to encoder with the difference in that it generates a sequence, instead of modeling it, so it will infer inputs one by one; therefore it cannot be bi-directional.
class DecoderRNN(nn.Module):
def __init__(self, vocab_size, hidden_size, n_layers=1):
super(DecoderRNN, self).__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.embedding = nn.Embedding(vocab_size, hidden_size)
init.normal_(self.embedding.weight, 0.0, 0.2)
self.lstm = nn.LSTM(hidden_size, hidden_size, num_layers=n_layers, batch_first=True, bidirectional=False)
def forward(self, word_inputs, hidden):
# Note: we run this one by one
# embedded (batch_size, 1, hidden_size)
embedded = self.embedding(word_inputs).unsqueeze_(1)
output, hidden = self.lstm(embedded, hidden)
return output, hidden
Test
To make sure the Encoder and Decoder models are working (and working together) I did a quick test with fake word inputs:
vocab_size = 10
hidden_dim = 10
n_layers = 2
encoder_test = EncoderRNN(vocab_size, hidden_dim, n_layers)
print(encoder_test)
# Recurrent network requires initial hidden state
encoder_hidden = encoder_test.init_hidden(1)
# Test input of size (1x3), one sequence of size 3
word_input = torch.LongTensor([[1, 2, 3]])
if USE_CUDA:
encoder_test.cuda()
word_input = word_input.cuda()
encoder_outputs, encoder_hidden = encoder_test(word_input, encoder_hidden)
# encoder_outputs: (batch_size, seq_length, hidden_size)
# encoder_hidden[0, 1]: (n_layers*2, batch_size, hidden_size/2)
print(encoder_outputs.shape, encoder_hidden[0].shape, encoder_hidden[1].shape)
EncoderRNN(
(embedding): Embedding(10, 10)
(lstm): LSTM(10, 5, num_layers=2, batch_first=True, bidirectional=True)
)
torch.Size([1, 3, 10]) torch.Size([4, 1, 5]) torch.Size([4, 1, 5])
encoder_hidden is a tuple for h and c components of LSTM hidden state. In PyTorch, tensors of LSTM hidden components have the following meaning of dimensions:
- First dimension is
n_layers * directions, meaning that if we have a bi-directional network, then each layer will store two items in this direction. - Second dimension is a batch dimension.
- Third dimension is a hidden vector itself.
The decoder uses a single directional LSTM, therefore we need to reshape encoders h and c before sending them into decoder: concatenate all bi-directional vectors into single-direction vectors. This means, that every two vectors along n_layers*directions I combined into a single vector, increasing the size of the hidden vector dimension in two times and decreasing a size of the first dimension to n_layers, which is two.
It is important to understand, how the reshaping is done7. Torch documentation is not vocal enough about this question, but you can refer to Numpy documentation for explanation. Basically, default reshape approach (C-order) starts moving elements from the last index and steadily change them from latter to starter indexes.
What does it mean for our case? In this example I have the hidden state of endoder LSTM with one batch, two layers and two directions, and 5-dimensional hidden vector. It has a shape (4,1,5). I need to reshape it into an initial hidden state of decoder LSTM, which should has one batch, a single direction and two layers, and 10-dimensional hidden vector, final shape is (2,1,10). To do that with torch.reshape I need to swap an order of dimensions first to have tensor with shape (1,4,5), reshape it to (1,2,10) and then change order back to (2,1,10). If I did this without changing the dimensions order, values from different batches would be mixed together, and thought vector would not be representation of a source sentence anymore.
decoder_test = DecoderRNN(vocab_size, hidden_dim, n_layers)
print(decoder_test)
word_inputs = torch.LongTensor([[1, 2, 3]])
decoder_hidden_h = encoder_hidden[0].permute(1, 0, 2).reshape(1, 2, 10).permute(1, 0, 2)
decoder_hidden_c = encoder_hidden[1].permute(1, 0, 2).reshape(1, 2, 10).permute(1, 0, 2)
if USE_CUDA:
decoder_test.cuda()
word_inputs = word_inputs.cuda()
for i in range(3):
input = word_inputs[:, i]
decoder_output, decoder_hidden = decoder_test(input, (decoder_hidden_h, decoder_hidden_c))
decoder_hidden_h, decoder_hidden_c = decoder_hidden
print(decoder_output.size(), decoder_hidden_h.size(), decoder_hidden_c.size())
DecoderRNN(
(embedding): Embedding(10, 10)
(lstm): LSTM(10, 10, num_layers=2, batch_first=True)
)
torch.Size([1, 1, 10]) torch.Size([2, 1, 10]) torch.Size([2, 1, 10])
torch.Size([1, 1, 10]) torch.Size([2, 1, 10]) torch.Size([2, 1, 10])
torch.Size([1, 1, 10]) torch.Size([2, 1, 10]) torch.Size([2, 1, 10])
Seq2seq
The logic to coordinate this two modules I stored in a high-level module Seq2seq; it takes care of Encoder-Decoder coordination and a transformation of decoder results into a word probability distribution.
Also, this module implements two forward functions: one is for training time and second is for inference. The difference between these two functions is that during training I am using training y values (target sentence words) as decoder input; this is called Teacher Forcing. Obviously, during inference, I don’t have y values, so I need a separate method for it.
class Seq2seq(nn.Module):
def __init__(self, input_vocab_size, output_vocab_size, hidden_size, n_layers):
super(Seq2seq, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.encoder = EncoderRNN(input_vocab_size, hidden_size, self.n_layers)
self.decoder = DecoderRNN(output_vocab_size, hidden_size, self.n_layers)
self.W = nn.Linear(hidden_size, output_vocab_size)
init.normal_(self.W.weight, 0.0, 0.2)
self.softmax = nn.Softmax()
def _forward_encoder(self, x):
batch_size = x.shape[0]
init_hidden = self.encoder.init_hidden(batch_size)
encoder_outputs, encoder_hidden = self.encoder(x, init_hidden)
encoder_hidden_h, encoder_hidden_c = encoder_hidden
self.decoder_hidden_h = encoder_hidden_h.permute(1,0,2).reshape(batch_size, self.n_layers, self.hidden_size).permute(1,0,2)
self.decoder_hidden_c = encoder_hidden_c.permute(1,0,2).reshape(batch_size, self.n_layers, self.hidden_size).permute(1,0,2)
return self.decoder_hidden_h, self.decoder_hidden_c
def forward_train(self, x, y):
decoder_hidden_h, decoder_hidden_c = self._forward_encoder(x)
H = []
for i in range(y.shape[1]):
input = y[:, i]
decoder_output, decoder_hidden = self.decoder(input, (decoder_hidden_h, decoder_hidden_c))
decoder_hidden_h, decoder_hidden_c = decoder_hidden
# h: (batch_size, vocab_size)
h = self.W(decoder_output.squeeze(1))
# h: (batch_size, vocab_size, 1)
H.append(h.unsqueeze(2))
# H: (batch_size, vocab_size, seq_len)
return torch.cat(H, dim=2)
def forward(self, x):
decoder_hidden_h, decoder_hidden_c = self._forward_encoder(x)
current_y = SOS_idx
result = [current_y]
counter = 0
while current_y != EOS_idx and counter < 100:
input = torch.tensor([current_y])
decoder_output, decoder_hidden = self.decoder(input, (decoder_hidden_h, decoder_hidden_c))
decoder_hidden_h, decoder_hidden_c = decoder_hidden
# h: (vocab_size)
h = self.W(decoder_output.squeeze(1)).squeeze(0)
y = self.softmax(h)
_, current_y = torch.max(y, dim=0)
current_y = current_y.item()
result.append(current_y)
counter += 1
return result
Training
To optimize neural network weights I need to have a model itself and optimizer. Model is already defined and the optimizer is usually available in the NN framework. I used Adam from torch.optim.
from torch.optim import Adam
model = Seq2seq(len(source_vocab), len(target_vocab), 300, 1)
optim = Adam(model.parameters(), lr=0.0001)
Since neural network training is a computationally expensive process, it is better to a train neural network for multiple examples at once. Therefore I need to split the training data on mini-batches.
import math
def batch_generator(batch_indices, batch_size):
batches = math.ceil(len(batch_indices)/batch_size)
for i in range(batches):
batch_start = i*batch_size
batch_end = (i+1)*batch_size
if batch_end > len(batch_indices):
yield batch_indices[batch_start:]
else:
yield batch_indices[batch_start:batch_end]
Previously I mentioned a log-likelyhood function which is used to optimize model parameters; in PyTorch this function is implemented in module CrossEntropyLoss:
cross_entropy = nn.CrossEntropyLoss()
To evaluate the performance of our network I should use a translation quality metric. Standard selection for neural machine translation would be previously mentioned BLEU - bilingual evaluation understudy. This metric is proven to have the most correlation with a human judgment of translation quality.
What is important to understand that BLEU is looking how many common phrases (n-grams) are shared between a model translation and multiple correct translation references. This could be unigrams (phrases of one word) in BLEU-1, bigrams (two words) in BLEU-2 and so on. Since my dataset is relatively small for a neural model, I used less restrictive BLEU-1 as the main metric.
from nltk.translate.bleu_score import corpus_bleu
def bleu(n):
weights = [1.0/n]*n + [0.0]*(4-n)
return lambda list_of_references, list_of_hypothesis: corpus_bleu(list_of_references, list_of_hypothesis, weights)
def accuracy(list_of_references, list_of_hypothesis):
total = 0.0
for references, hypothesis in zip(list_of_references, list_of_hypothesis):
total += 1.0 if tuple(hypothesis) in set(references) else 0.0
return total / len(list_of_references)
score_functions = {'BLEU-{}'.format(i):bleu(i) for i in range(1, 5)}
score_functions['Accuracy'] = accuracy
def score(model, X, target, desc='Scoring...'):
scores = {name:0.0 for name in score_functions.keys()}
length = len(target)
list_of_hypothesis = []
for i, x in tqdm(enumerate(X),
desc=desc,
total=length):
y = model(x.unsqueeze(0))
hypothesis = target_vocab.unidex_words(y[1:-1]) # Remove SOS and EOS from y
list_of_hypothesis.append(hypothesis)
for name, func in score_functions.items():
score = func(target, list_of_hypothesis)
scores[name] = score
return scores
Finally, I can train my model. Each training epoch includes a forward propagation, which yields some training hypothesis for training source sentences; then cross_entropy calculates loss for this hypothesis and loss.backward() calculates gradient with respect to the loss for each model parameter. After that, optim.step() uses the gradient to adjust model parameters and minimize loss.
After each training epoch, the development set is used to evaluate model performance. I used early_stop_counter to stop the training process if BLEU-1 is not getting better for 10 epochs.
Module tqdm is optional to use, it is a handy and simple way to create a progress bar for long operations.
from tqdm import tqdm_notebook as tqdm
BATCH_SIZE = 100
total_batches = int(len(x_training)/BATCH_SIZE) + 1
indices = list(range(len(x_training)))
early_stop_after = 10
early_stop_counter = 0
best_model = None
best_score = 0.0
scoring_metric = 'BLEU-1'
scores_history = []
loss_history = []
for epoch in range(10000):
# Training
total_loss = 0.0
for step, batch in tqdm(enumerate(batch_generator(indices, BATCH_SIZE)),
desc='Training epoch {}'.format(epoch+1),
total=total_batches):
x = x_training[batch, :]
# y for teacher forcing is all sequence without a last element
y_tf = y_training[batch, :-1]
# y for loss calculation is all sequence without a last element
y_true = y_training[batch, 1:]
# (batch_size, vocab_size, seq_length)
H = model.forward_train(x, y_tf)
loss = cross_entropy(H, y_true)
assert loss.item() > 0
optim.zero_grad()
loss.backward()
optim.step()
total_loss += loss.item()
loss_history.append(total_loss/total_batches)
print('Epoch {} training is finished, loss: {:.4f}'.format(epoch+1, total_loss/total_batches))
desc = 'Validating epoch {}'.format(epoch+1)
scores = score(model, x_development, dev_target, desc=desc)
scores_str = '\n'.join(['{}: {:.4f}'.format(name, score) for name, score in scores.items()])
scores_history.append(scores)
print ('Epoch {} validation is finished.\n{}'.format(
epoch+1, scores_str
))
metric = scores[scoring_metric]
# Early Stop
if metric > best_score:
early_stop_counter = 0
print('The best model is found, resetting early stop counter.')
best_score = metric
best_model = model
else:
early_stop_counter += 1
print('No improvements for {} epochs.'.format(early_stop_counter))
if early_stop_counter >= early_stop_after:
print('Early stop!')
break
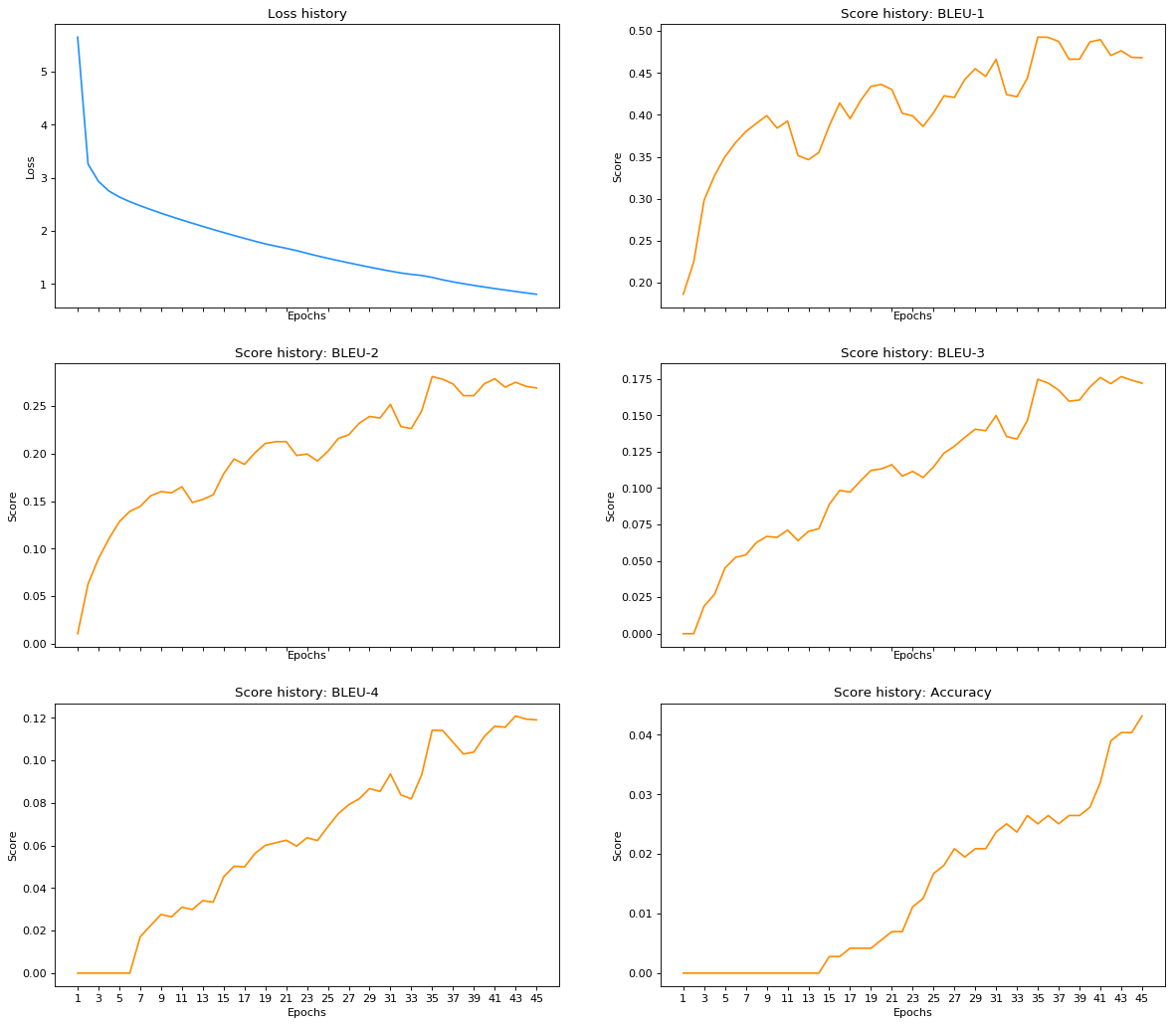
Epoch 45 training is finished, loss: 0.8080
Epoch 45 validation is finished.
BLEU-1: 0.4683
BLEU-2: 0.2692
BLEU-3: 0.1720
BLEU-4: 0.1190
Accuracy: 0.0432
No improvements for 10 epochs.
Early stop!
I prepared some plots to get a visual understanding of how a validation score changed during training.
import matplotlib.pyplot as plt
%matplotlib inline
nrows = 3
ncols = 2
fig, ax = plt.subplots(nrows, ncols, sharex=True, figsize=(18, 16), dpi= 80,)
epochs = list(range(1, epoch+2))
epochs_ticks = list(range(1, epoch+2, 2))
i = 0
j = 0
ax[i][j].plot(epochs, loss_history, color='dodgerblue')
ax[i][j].set_title('Loss history')
ax[i][j].set_xlabel('Epochs')
ax[i][j].set_xticks(epochs_ticks)
ax[i][j].set_ylabel('Loss')
for name in score_functions.keys():
j += 1
if j >= ncols:
j = 0
i += 1
score_history = [s[name] for s in scores_history]
ax[i][j].plot(epochs, score_history, color='darkorange')
ax[i][j].set_title('Score history: {}'.format(name))
ax[i][j].set_xlabel('Epochs')
ax[i][j].set_xticks(epochs_ticks)
ax[i][j].set_ylabel('Score')
plt.show()
Here are some examples of translation from my model.
examples = zip(dev_source[:10], dev_target[:10], x_development[:10])
for source, target, x in examples:
y = model(x.unsqueeze(0))
translation = ' '.join(target_vocab.unidex_words(y[1:-1]))
source = ' '.join(source)
references = '\n'.join([' '.join(t) for t in target])
print('Source: "{}"\nReferences:\n{}\nTranslation: "{}"\n'.format(source, references, translation))
Source: "їм потрібний том ."
References:
sie wollen tom .
Translation: "tom hat angst ."
Source: "бог існує ?"
References:
gibt es gott ?
Translation: "ist die wurdest ?"
Source: "він написав листа ."
References:
er hat einen brief geschrieben .
er schrieb einen brief .
Translation: "er hat einen brief geschrieben ."
Source: "я не говорю німецькою ."
References:
ich spreche kein deutsch .
ich spreche nicht deutsch .
Translation: "ich spreche kein deutsch ."
Source: "у вас є татуювання ?"
References:
haben sie eine tätowierung ?
Translation: "haben sie ein bisschen ?"
Source: "це копія ."
References:
das ist eine kopie .
Translation: "es ist eine langweilig ."
Source: "у мене є брат - близнюк ."
References:
ich habe einen zwillingsbruder .
Translation: "ich habe eine familie ."
Source: "мені подобається світло свічок ."
References:
ich mag kerzenlicht .
Translation: "ich sehe gern ein neues ."
Source: "мають право ."
References:
es ist ihr recht .
Translation: "das gesetz ist ein ."
Source: "перепрошую , скільки це коштує ?"
References:
verzeihung , was kostet das ?
Translation: "wie geht es , das haben das ist ?"
Finally, each experiment should be evaluated with unseen data. When I selected best_model according to the best validation score, I made the model slightly overfit on validation data; therefore, to get a fair quality assessment I scored best_model on the test set.
test_scores = score(best_model, x_test, test_target)
scores_str = '\n'.join(['{}: {:.4f}'.format(name, score) for name, score in test_scores.items()])
print('Final score:\n' + scores_str)
Final score:
BLEU-1: 0.4855
BLEU-2: 0.2853
BLEU-3: 0.1814
BLEU-4: 0.1242
Accuracy: 0.0424
This is clearly a naive result which can not be used in production level translation system. But this enough to get a basic understanding of Encoder-Decoder approach. In following tutorials I will improve this model using different machine learning techniques and you will be able to learn practical aspects of NMT step by step.
-
This vector is called “thought vector” or “sentence vector” and this solution clearly has some drawbacks. I will present more complex technique to share information between encoder and decoder in the following tutorial. ↩
-
More information about LSTM can be found in Colah’s blog or in the original paper Hochreiter and Schmidhuber, 1997. ↩
-
For Ukrainian use vectors from lang-uk project. For other languages, I recommend FastText embeddings. ↩
-
The previous version of this article has an error because of incorrect reshape. ↩